Classification task
Template code link
To get you started we created a repository that contains the minimum code for running your algorithm, and it can be found here: https://gitlab.com/arise-biodiversity/DSI/algorithms/arise-challenge-algorithm-template.Data
The training set for the classification tasks consists of 39,445 examples of individual insects. The insects are provided as images cropped from the original screen images. Examples are labeled at the most specific taxonomic level possible, giving 84 “leaf” classes. Additionally, we provide a CSV file that gives the ancestors (all parents) of a taxon, which can be used to construct hierarchical outputs. The public DIOPSIS classification data with images, labels, and the mapping from name to ancestors can be found here.
Expected output
Each insect should be assigned a hierarchical probabilistic classification: a list of taxa with associated probabilities as follows.
| Level 0 | Level 1 | Level 2 | Level 3 | Level 4 | |||||
| Insecta (99%) | Lepidoptera (99%) | Nymphalidae (95%) | Aglais (90%) | Aglais io (90%) |
The deeper levels of the taxonomy can be omitted if the algorithm considers a certain taxonomic level to be the most specific that can be reliably determined, for example
| Level 0 | Level 1 | Level 2 | Level 3 | Level 4 | |||||
| Insecta (99%) | Lepidoptera (99%) | Nymphalidae (95%) |
Evaluation
A script for evaluating the performance of the insect identification model using different performance measures can be found here. The same script will be used to compute the measures on the hold-out test set. Please note that the script might be updated during the first phase of the challenge. We will update you when this happens and let you know when the final script is ready. Below, we describe the performance measures.
Accuracy
The accuracy is the percentage of insects correctly classified. This indicates how good the model is overall but is mainly determined by the majority classes.
Avg. recall/precision/F1
To indicate how well the model performs across different classes, independent of how many examples there are, averages are computed for the recall, precision, and F1 metric which have been first calculated per class. A model with high scores for these measures also performs well for minority classes.
Avg. recall/precision/F1 in relation to number of training examples
An extra indication of how well the model performs for classes with few examples is the performance for groups of taxa with different amounts of training examples. Avg. recall/precision/F1 will be computed for taxa with 1-5 / 6 - 10 / 11 - 20 / 21 - 50 / 51 - 100 / 100+ training examples< /p>
Taxon distance
Because the labels are hierarchical, wrong classification results can be divided into different incorrect categories: partly wrong - too general or too specific - or completely wrong in an other branch of the taxonomic tree. The evaluation script will compute percentages of errors of being too general, too specific, or in other branches. The taxon distance is another custom metric for hierarchical labels and is defined as the number of edges that need to be traversed to go from the true taxon to the predicted taxon in the taxonomic tree. The evaluation script will compute the average taxon distance overall and per incorrect category. See figure 4 for a visual explanation.
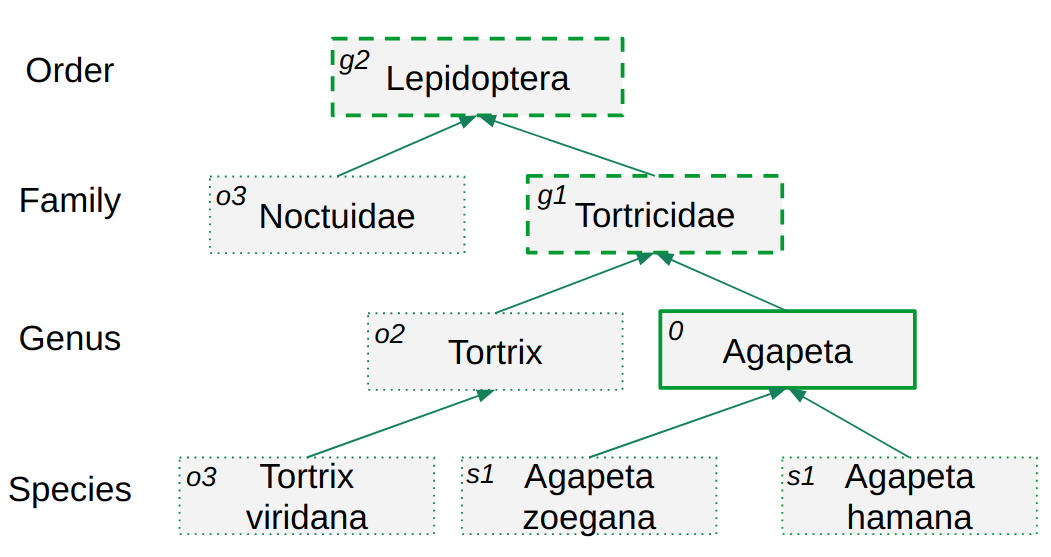 Example of a taxonomic tree with taxon distances indicated. The taxon distance is the number of edges between the true taxon (Agapeta) and other taxa. The true taxon is indicated by a solid line, the taxa Tortricidae and Lepidoptera are part of the complete taxonomy of Agapeta and not strictly incorrect, but are too general. s1 means a taxon distance of 1 on a too specific path. g1 and g2 indicate predictions that are too general at a distance of respectively 1 and 2 nodes from the true taxon, o2, and o3 refer to taxon distances of respectively 2 and 3 edges in another branch.
Example of a taxonomic tree with taxon distances indicated. The taxon distance is the number of edges between the true taxon (Agapeta) and other taxa. The true taxon is indicated by a solid line, the taxa Tortricidae and Lepidoptera are part of the complete taxonomy of Agapeta and not strictly incorrect, but are too general. s1 means a taxon distance of 1 on a too specific path. g1 and g2 indicate predictions that are too general at a distance of respectively 1 and 2 nodes from the true taxon, o2, and o3 refer to taxon distances of respectively 2 and 3 edges in another branch.
Expected calibration error
For practical applications of machine learning models, the probability computed by the algorithm for a prediction must be well calibrated. In a well-calibrated system, results that have high probabilities should be, on average, more often correct than results that have low probabilities. The evaluation script will compute the expected calibration error (ECE) (Nixon et al. 2019) as a measure of calibration accuracy.
Overall metric
From all the different metrics one overall metric is computed according to weighting factors for all individual metrics. The overall metric is used to rank submissions on the leaderboard. See the evaluation scripts for the details of the computation of the overall metric.