Introduction
The goal of this challenge is to develop improved algorithms for the detection and classification step of the DIOPSIS image processing pipeline. The goal is to outline all insects visible on the screen for detection. The main challenges are the large number of insects on a screen, the large range of sizes (from a few mm to several centimeters), overlapping insects, and the presence of non-insect structures on the screen, such as vegetation, dirt, shadow patterns, etc. The main challenges for the classification (species recognition) part are the large imbalance in the number of training examples per species, the fine-grained nature of the task, the appropriate taxonomic level to output results, and the relatively poor image quality. The large imbalance is shown in the figure below.
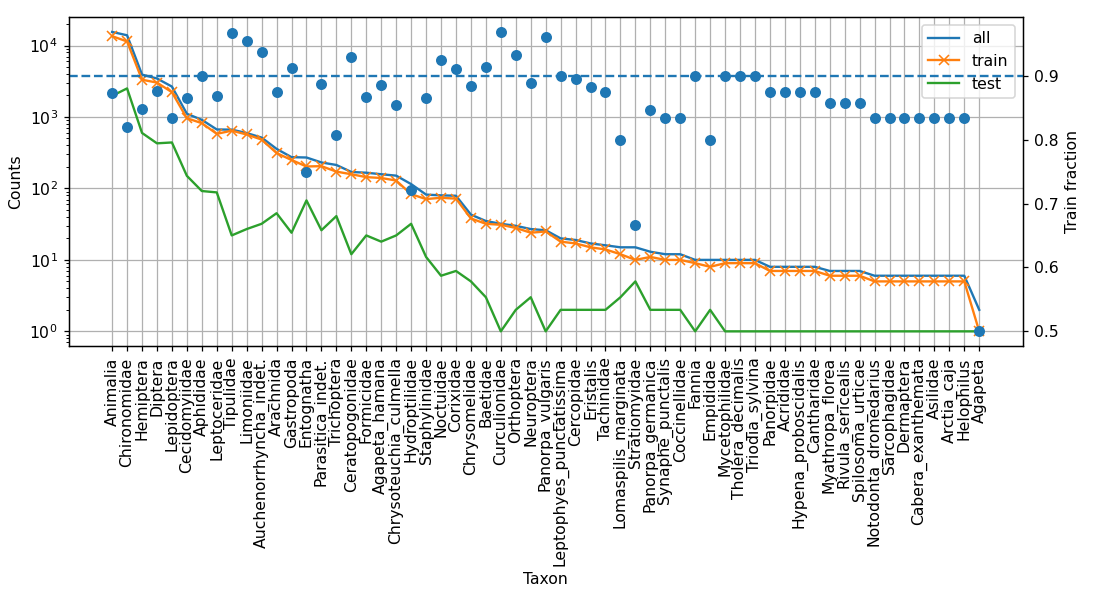 Counts per class (taxon) showing the large imbalance between classes. Note the log scale on the y-axis.
Counts per class (taxon) showing the large imbalance between classes. Note the log scale on the y-axis.
Fine-grained classification means that differences between classes (taxa) can be subtle, and the algorithm should be able to learn the differences. This difficulty is exacerbated by the imbalanced data and the relatively poor image quality. The taxonomic level refers to the hierarchical nature of the data. In biology, data is organized in a hierarchical structure called a taxonomy. The most detailed level in the taxonomy is the species level. Still, in some cases, image data can only reliably be classified at higher levels, such as genus, family, or order. The name of the insect in a taxonomy is called a taxon. In the case of diopsis, the data has been assigned a mix of taxa from different levels. The relatively poor quality of the images results from a tradeoff between the camera costs, camera resolution, and screen size. This results in a limited level of detail and makes it harder to identify smaller insects and insects with small identifying features.
Data
The full annotated DIOPSIS dataset consists of 3,965 images of screens (resolution 3280 x 2464 pixels) with a total of 48,216 labeled (box + taxa) insects. A part of the data (+/- 10%) is kept secret as the test (hold-out) set and will be used to evaluate the submitted algorithms on the challenge platform. The remaining part of the data (90%) is available for training and tuning the algorithms by the participants.
Tasks and phases
The challenge comprises two tasks: detection and classification. The detection task will be described in a later version of this document (or in the detection phase on the challenge website). In the challenge, the tasks are divided into phases. You can submit an algorithm to each phase, each with its leaderboard. You can use the preliminary phase to test your algorithm container and verify its interfaces.
Preliminary classification phase
In the preliminary phase you can get familiar with the algorithm submission procedure before submitting to the final test phase.